GCL学术成果:SIGGRAPH Asia 2025-视觉引导的高质量3D场景布局生成
【论文标题】Imaginarium: Vision-guided High-Quality 3D Scene Layout Generation
【作者】朱晓明1,黄旭2,谢庆红冰1,邓治2,余骏晟2,关一锐2,刘中远2,朱琳2,赵齐军2,刘利刚3,曾龙1
【单位】清华大学1,腾讯游戏2,中国科学技术大学3
背景与问题
在数字内容创作中,特别是游戏场景生成和电影计算机生成图像领域,从预定义的资产集合中生成逻辑连贯且丰富的自定义3D场景布局是一项具有挑战性的任务。
传统方法通常将其视为一个复杂的基于图的优化问题,通过从预建的布局分布中采样,并利用预定义的场景先验(如布局指南、对象类别分布)进行迭代优化。然而,定义精确的规则既耗时又需大量的艺术专业知识。此外,预定义规则限制了复杂和多样场景组合的表达。基于深度学习的方法通过从预建的三维场景布局数据集中学习布局生成。然而,由于收集三维数据的高成本、隐私问题和耗时性,当前数据集仍然相对有限,这导致生成的结果缺乏多样性,无法完全满足艺术专家的实际需求。这种数据短缺在新游戏或电影制作中尤为明显,因此难以提前准备多样化和高质量的三维场景布局,限制了基于原生三维数据训练的生成器的应用范围。近期基于大语言模型的场景生成方法虽然通过语言模型提取布局先验,但在空间感知和几何精度上仍有不足,难以准确表示复杂的空间关系、建模对象姿态,并符合美学设计原则。此外,现有的资产库,如 Objaverse 和 3D Future,常因网格质量差、样式选择有限以及对复合资产的依赖而限制了布局的灵活性。
为此,我们首先构建了一个高质量的3D资产库,并期望基于此资产库,搭建一个3D场景布局系统:在给定某个高质量的3D资产库的情况下,从文本或图像输入下,即可生成自然、细致且逻辑连贯的3D场景布局。

解决方案
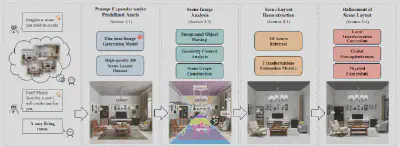
首先,我们使用图像生成模型 Flux 将用户的输入提示扩展为引导图像。通过我们构建的高质量3D场景布局数据进行微调,Flux能够生成质量更高且与资产集合风格更一致的图像,这将显著提高了摆放系统的可控性。接下来,我们构建了一个基于预训练视觉模型的图像分析模块,该模块融合了视觉语义分割、单图像几何解析以及基于图的场景图逻辑构建功能。之后,我们根据语义特征匹配策略,从资产集合中检索出与引导图像最匹配的对象。结合视觉语义特征、几何信息和场景布局逻辑,我们迭代计算每个前景对象的旋转、平移和缩放变换。最终,我们通过场景图逻辑和图像语义解析对三维场景布局进行一致性优化,确保最终3D场景在视觉和逻辑上与引导图像相近。
我们3D资产由自主开发的模型、高质量的开源内容及授权市场资产组合而成,并由20名具有三年以上经验的专业艺术家将这些项目布置成游戏级别的3D场景。

图像生成模型擅长生成美观且细致的二维布局,我们的方法可将这些能力应用于三维场景布局任务。与之前依赖复合资产的方法不同,我们根据引导图像以不同的姿态和位置放置资产,避免了冗余,增加了多样性。此外,我们引入了资产内部布局功能,使资产可在其他资产内进行排列,以优化空间使用并提高场景真实性。这些功能使得生成的三维场景布局更加自然、详细和具备视觉吸引力。实验结果显示,与以往的方法相比,我们的3D场景布局质量有显著提升。
实验结果
3D场景布局结果对比:我们生成的3D场景布局在丰富度和美术质量方面优于其他先进方法,受到了更多专业人士的青睐。这一成果使原本需要专业美术师耗费2.5小时完成的工作流程实现了自动化,并有望将所需时间降低至4分钟以内。

位姿估计结果对比:在3D场景布局情境下的开放集合旋转位姿估计任务中,我们设计的位姿估计方案优于其他先进方法。该算法模块的高效精准性是确保我们系统稳定运行的关键因素。

技术贡献
本项工作的主要贡献包括:
-
搭建了一套视觉引导的3D场景布局系统,能够基于文本或图像输入生成高质量的3D场景布局。
-
建立了一个高质量的三维场景布局数据集,其中包含约2000个高质量3D资产和147个精致的3D场景布局,并计划将该数据集向社区开源。
-
提出了一种结合视觉语义与几何信息的鲁棒姿态估计算法,可有效缓解场景中复杂的物体遮挡问题。
论文发表
该工作已被计算机图形学顶会SIGGRAPH Asia 2025接收,并将发表于顶级期刊《ACM Transactions on Graphics》。该期刊2024-2025年度影响因子为7.8,是计算机科学与软件工程领域的一区刊物之一。
论文原文
Xiaoming Zhu, Xu Huang, Qinghongbing Xie, Zhi Deng, Junsheng Yu, Yirui Guan, Zhongyuan Liu, Lin Zhu, Qijun Zhao, Ligang Liu, Long Zeng. Imaginarium: Vision-guided High-Quality 3D Scene Layout Generation. ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 44(6), Article: 257, 2025.