GCL学术成果:SIGGRAPH Asia 2025-基于可学习嵌入的泛化扩散数字人头模型
【论文标题】Constructing Diffusion Avatar with Learnable Embeddings
【作者】高玄,周敬涛,刘东宇,周玉祺,张举勇
【单位】中国科学技术大学
背景与问题
泛化的人头建模在AR/VR、影视和娱乐等行业中具有广泛的应用前景。然而,要在确保高保真渲染的同时,兼顾三维一致性、时间一致性以及身份泛化能力,仍然是一个重大挑战。构建强大的头部生成模型,关键取决于头部的表示方式、生成模型的训练策略,以及训练数据的多样性与质量。
早期的泛化人头建模方法多采用网格(mesh)来表示头部,但这种方式存在建模非面部区域困难、渲染效果不真实等问题。随后,一些研究引入隐式函数或三维高斯表示,在渲染效果上取得了进展。然而,这些方法大多采用一对一的映射范式,难以捕捉控制信号与渲染结果之间的一对多关系,严重限制了模型的表现力与泛化能力。
近年来,扩散模型在应对一对多生成问题上展现了巨大潜力,但其结果依然存在泛化性不足和精度欠缺的问题。这些不足主要源于以下几点根本原因:
(1)控制信号表达能力有限:常用的关键点过于稀疏,难以刻画精细的肌肉运动与头部姿态;深度图和法线图虽能提供几何信息,但高度依赖相机视角,缺乏三维一致性。这样的信号一旦输入扩散模型,会导致生成结果在几何结构与外观上都缺乏准确性。
(2)数据多样性与分布不足:现有公开数据集中,身份、姿态和表情的覆盖范围有限,模型在训练时往往“见得太少”,导致在遇到新身份和夸张视角时合成结果不令人满意。
本文围绕如何设计扩散模型控制信号,以及如何让模型自适应利用合成数据集两方面给出方案,提出了一种新型的基于可学习嵌入的泛化扩散数字人头模型。
解决方案
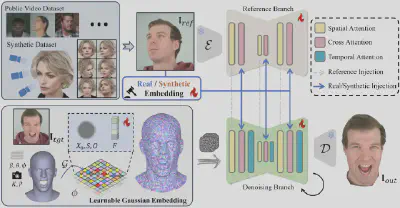
本工作主要由三部分构成,一是可学习的高斯人头控制信号,二是参考图片引导的扩散模型,三是合成数据的利用策略。
(1)可学习的高斯人头控制信号
我们在参数化人头的UV空间中维护一个三维高斯场,并根据底层网格的形变带动高斯改变。具体地,在UV域中定义可学习高斯场,其中每个像素具有可学习特征、不透明度和尺度三个属性。通过UV映射,可将这些可学习高斯从UV空间变换到三维空间。给定相机参数后,通过对重叠的三维高斯进行排序与混合,得到投影到二维的特征图。随后,该特征图被作为扩散模型的控制信号使用。与以往使用关键点、法线图或深度图等视觉线索作为控制信号的方法相比,我们的控制信号具有以下优势:
稠密:不同于稀疏的关键点表示,投影的特征图提供了稠密的头部编码,能够捕捉精细的肌肉形变。
自适应:高斯与去噪网络的联合优化使模型可以自主学习如何解释局部几何特征,从而显著提高控制精度。
表达力强:以可学习神经特征替代颜色,使表面能够映射到高维特征空间,重叠的高斯可呈现更复杂、富有表现力的模式。
三维一致:法线图与深度图本质上依赖相机参数,缺乏三维一致性,会增加去噪网络学习负担并带来不一致的生成结果。本文的高斯控制信号是与视角无关的表示,可以进一步促进三维一致性。
便于跨身份驱动:参数化头模在身份与表情空间上是解耦的;在跨身份驱动任务中,只需将控制信号中的形状系数替换为参考身份的形状系数即可。
(2)参考图片引导的扩散模型
利用上述可学习控制信号,参数序列被映射为特征图序列,并通过参考引导的去噪框架学习与目标图像之间的对应关系。该框架采用参考分支与去噪分支的双分支结构:在参考分支中,参考图像首先被参考网络(Reference Network)提取多尺度特征,然后通过共享注意力注入到去噪分支对应的网络块中,以增强细节保真度;在去噪分支中,带噪隐编码与控制信号共同作为输入,去噪网络(Denoising Network)基于控制信号和参考支的信息对带噪隐编码进行降噪。
(3)合成数据的利用
传统说话人脸数据集在姿态和表情上受限,训练出的模型对大姿态缺乏鲁棒性。现有多视角数据集身份数量有限,也难以支撑泛化。本研究采用三维人头生成器SphereHead合成大规模静态多视角数据,在身份与姿态上更为多样,显著提升泛化能力。为解决合成数据缺陷对模型生成质量的影响,我们提出真实/合成嵌入:在训练时为每张图像分配来源标签,并引入对应标签的嵌入送入交叉注意力模块。推理时仅使用真实标签,从而既能利用合成数据的多样性,又能保证真实感。
实验结果
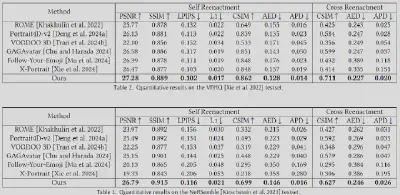
我们与之前的工作在VFHQ数据集和NeRSemble数据集上做了对比,发现我们的模型在身份保持性和表情精准性上有显著优势。

给定一张参考图片,我们也可以自由地控制相机,以此来实现新视角合成的效果:

技术贡献
在这项工作中,我们的贡献主要包括:
-
我们提出了一种新的人头控制信号。不同于现有的依赖关键点、深度图和法向图的方法,我们利用带有可学习高斯嵌入的特征图,显著提升了生成结果的一致性和真实性。
-
为弥补公共数据集多样性的不足,我们在训练中引入合成数据,并设计了真实/合成嵌入机制,使模型能够充分利用合成数据的优势,同时消除合成数据缺陷对生成结果的影响。
-
实验表明,我们的模型在表达力和一致性方面均显著优于已有方法。需要指出的是,所提出的控制信号表示以及训练数据的合成与利用机制,也有望推广至更广泛的数字内容生成任务。
论文发表
该工作已被计算机图形学顶会SIGGRAPH Asia 2025接收。
论文原文
Xuan Gao, Jingtao Zhou, Dongyu Liu, Yuqi Zhou, Juyong Zhang. Constructing Diffusion Avatar with Learnable Embeddings. ACM SIGGRAPH Asia 2025 Conference Proceedings.