GCL学术成果:SIGGRAPH Asia 2024-基于多模态生成式先验的人像视频编辑
【论文标题】Portrait Video Editing Empowered by Multimodal Generative Priors
【作者】高玄,肖海尧,钟承来,胡诗敏,郭玉东,张举勇
【单位】中国科学技术大学
【背景与问题】
人像视频编辑在电影、艺术和增强现实/虚拟现实等领域具有广泛的应用。如何确保被编辑视频的结构相似性和时间一致性,同时实现高质量、多模态的编辑效果,一直是备受关注的重要问题。
2D人像编辑已经被广泛研究。早期的工作主要采用GAN进行人像编辑或者人像动画生成,然而,这类工作受到GAN模型表示能力的限制,生成的人像质量往往不高。最近,降噪扩散模型在图片生成能力上展示了优于GAN的性能。然而,直接将这些图片生成工作用于视频编辑,往往很难保持帧间的时间一致性。为了进一步提升所编辑视频的连续性,一些工作尝试在时间维度上连接帧,并训练时间注意力模块以确保时间或多视角一致性。然而,由于缺乏三维先验和面部/身体先验,它们可能无法生成在质量和时间一致性上令人满意的视频结果。
本文提出了PortraitGen框架,给定一个人像视频,基于多模态提示词实现高质量人像视频编辑。本方法在时域连续性、三维一致性等方面都超过了之前的工作。

【解决方案】
不同于之前的二维视频编辑方案,我们将二维的人像视频提升到动态三维场,通过在三维空间上对人像进行表示和编辑,以此来保证三维一致性和时域连续性。我们先使用参数化人体几何模型SMPL-X对视频中的人进行跟踪,得到参数化人体几何序列,然后在人体几何表面嵌入三维高斯场,以此来实现人像的高质量表征和可微的人像视频渲染。我们使用迭代数据集更新技术,交替执行数据集视频帧编辑和三维人像更新,将二维多模态生成模型的编辑蒸馏到三维上。
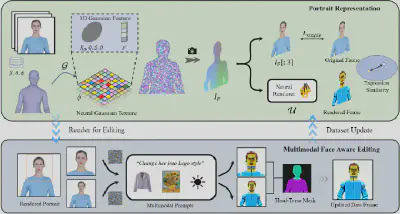
我们设计了一种神经高斯纹理机制(Neural Gaussian Texture,简称NGT),给每一个高斯存储了一个可学习的特征,然后将渲染后的图片通入给一个神经渲染器,以此来建模复杂的人像风格,尤其是具有非三维一致属性的人像风格:

【实验结果】
本工作适用于各类保结构的多模态生成模型,我们通过文本编辑、图像编辑和重打光三个任务,验证了我们的方法的有效性。
【技术贡献】
我们提出了PortraitGen,一个高质量的人像视频编辑系统。通过将二维人像视频编辑问题提升到三维,并引入三维人像先验知识,有效地保证了编辑视频的三维一致性和时间一致性。
我们的神经高斯纹理机制能够使几何基元蕴含更丰富的三维信息,可以提高人像的渲染质量,并可以支持复杂的风格。
我们的表情相似性引导项和面部感知人像编辑模块可以有效处理迭代数据集更新过程中的退化问题,进一步提高表情质量并保持个性化的面部结构。
【论文发表】
该工作已被计算机图形学顶会SIGGRAPH Asia 2024 Conference Track接收。
【论文原文】
Xuan Gao, Haiyao Xiao, Chenglai Zhong, Shimin Hu, Yudong Guo, Juyong Zhang. Portrait Video Editing Empowered by Multimodal Generative Priors. ACM SIGGRAPH Asia 2024 Conference Proceedings.