GCL学术成果:SIGGRAPH Asia 2024—基于多视图一致性扩散模型的多视图转换方法
【论文标题】MV2MV: Multi-View Image Translation via View-Consistent Diffusion Models
【作者】蔡有城,李润时,刘利刚
【单位】中国科学技术大学
【背景与问题】
图像转换在计算机图形学和计算机视觉中有众多应用,目的是将图像从一个域转换到另一个域。由于扩散模型具有良好的生成能力,最近基于扩散模型图像转换方法获得了逼真的效果。然而,现有的图像转换方法通常侧重于单视图图像。虽然这些方法在各自的任务中对单视图图像处理产生了很好的结果,但在应用于多视图图像转换任务时却遇到了困难。这是因为简单地逐帧执行图像转换会遇到多视图一致性问题,从而导致不同视图之间的几何与外观的不一致。
最近的扩散模型在二维图像处理领域展示了强大的生成能力,并且出现了一系列通用的图像转换的方法,并取得了令人印象深刻的转换效果。这促使我们提出了一个有趣的问题:我们是否也可以利用扩散模型实现统一的多视图图像转换?直接在图像域上实现多视图图像转换能够更好地利用现有的二维生成先验,实现更灵活的处理,获得更真实的结果。
其存在两个主要挑战:第一个是对训练数据对的需求。利用真实数据进行有监督学习将有效增强模型的泛化能力,能够有效适应真实场景的复杂性和可变性。然而,收集真实世界的高质量/低质量多视图图像对通常非常昂贵或不可用的。第二个挑战是难以保证多视图一致性。扩散模型的生成特性导致在单独处理多视图图像时,不可避免地会为不同视图生成3D不一致的内容。
针对这两个挑战,我们的目标是构建一个统一的多视图图像到多视图图像的转换框架。

【解决方案】
为了解决上述挑战,我们提出了一个统一的基于扩散模型的多视角图像到多视角图像的转换框架,称为MV2MV,用于各种多视图图像转换任务,如超分辨率、去噪、去模糊和文本驱动的编辑。具体来说,我们构建多视图一致性扩散模型(VCDM)。首先,我们引入了一种新的自监督训练策略,称为一致性和对抗性监督策略。我们首先使用现有的单视角图像转换器单独处理多视图图像,以获得一组高质量的输出,然后将它们输入到3DGS来获得视角一致性的输出。将这两组输出结果作为伪Ground-truth作为监督信号,并引入一致性损失和对抗性损失,有效地结合了两组伪Ground-truth的优点,保证了一致性和高质量。其次,我们提出了一个潜在多视图一致性模块。潜在多视图一致性模块使用Latent-3DGS作为底层3D表示,保证多视角图像之间的信息交换,从而保证多视图生成的一致性,有效解决了视图一致性难以保证的问题。最后,我们引入了一种联合优化策略,通过同时训练VCDM和3DGS来保证对抗损失引导出的高频细节的一致性,从而更好地在图像一致性和真实性之间进行权衡。
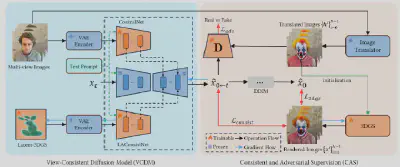
【实验结果】
提出的MV2MV是一个统一的多视图图像到多视图图像转换框架,支持各种图像转换任务。在我们的实验中,我们证明了MV2MV在各种任务中的有效性:超分辨率、去噪、去模糊和文本驱动编辑。




【技术贡献】
在该项工作中,我们的主要贡献包括:
1.一个统一的多视图图像到多视图图像的转换框架,能够在图像域上处理各种转换任务
2.生成式的一致性多视图扩散模型,可实现更好的视图一致性以及高质量的细节
【论文发表】
该工作已被计算机图形学顶会SIGGRAPH Asia 2024接收,并将发表于顶级期刊《ACM Transactions on Graphics》。该期刊2023-2024年度影响因子为7.8,是计算机科学与软件工程领域的一区刊物之一。
【论文原文】
Youcheng Cai, Runshi Li, Ligang Liu. MV2MV: Multi-View Image Translation via View-Consistent Diffusion Models. ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 43(6), 2024.