GCL学术成果:CVPR 2026-STAC:让VGGT学会 “挑着记”,破解流式三维重建显存膨胀难题
近日,CVPR 2026 接收成果出炉,中国科学技术大学数学科学学院 GCL 实验室刘利刚研究团队的王润泽、宋宇轩、蔡有城提出全新流式三维重建框架 ——STAC。该框架针对长序列输入下视觉几何大模型(Causal-VGGT)缓存持续膨胀的核心问题,通过设计时空感知的缓存重组与压缩机制,在无需额外训练前提下,实现了近 10 倍显存压缩与约 4 倍推理加速。在保持与完整缓存模型相当的重建质量与时序一致性的同时,有效突破了长序列流式重建的显存瓶颈,为实时三维重建、数字孪生等下游应用提供了新的技术范式。

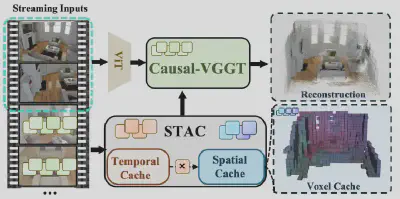
图1:STAC让流式三维重建从“笨重的记录者”变成了“精明的记忆大师”。
困局:大模型的“记忆危机”——记得越多,跑得越慢
想象一下,你正戴着一台AR眼镜,在房间里漫步。眼镜里的AI需要实时重建你眼前的世界,把每一幅画面、每一个角落都“记住”,才能在你转头时,准确地补全你背后的物体。

图2:流式三维重建 (图源:Lan et al. STream3R. 2026)
这个过程,就叫流式三维重建。它希望大模型能像人类一样,一边看,一边理解,一边构建持续、稳定的空间记忆。
最近,像VGGT这样的“前馈”模型让这件事看到了希望。它们把复杂的相机参数、深度信息、三维点云统统打包,变成一个端到端的“视觉几何大模型”。随后,StreamVGGT、STream3R等前沿工作,进一步把全局注意力改造成因果注意力架构(Causal- VGGT),搭配KV Cache(键值缓存)机制,让模型可以持续复用历史上下文信息,三维重建终于真正具备了流式推理的能力。
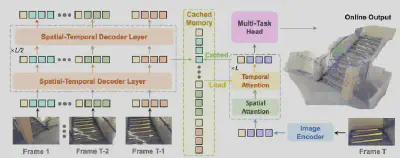
图3:Causal-VGGT框架像一条流水线,视觉信息经过处理后,不断存入“缓存”(Cached Memory)。(图源:Zhuo et al. StreamVGGT. 2025 )
但就在行业以为即将突破落地瓶颈时,一个无解的死循环出现了:
● 想要长时序重建的几何一致性,就必须保留完整的历史KV Cache;
● 可序列越长、缓存越积越多,显存占用就会线性暴涨,推理延迟持续走高;
● 要是为了省显存强行裁剪早期缓存,又会直接丢失长期上下文,重建场景直接“崩掉”,时序一致性荡然无存。
这就是流式3D重建始终无法“长跑”的核心死穴。就像测试数据呈现的那样:原始Causal-VGGT的单帧推理耗时,会随着序列长度从90ms一路飙升至257ms,显存更是直接突破20GB,普通消费级显卡根本无法承载。
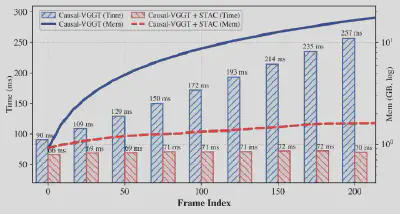
图4:随着序列增长,原始模型的“记忆”(缓存)膨胀,速度变慢;而STAC则始终轻盈、稳定。
这让我们不禁想问:AI真的需要记住一切吗?
破局:核心不是“记得更多”,而是“记得更准”
中科大团队在深入研究Causal-VGGT的“思考模式”后,发现了一个关键秘密:大模型的注意力,从来都不是平均分配的。它就像我们在阅读时,会重点关注某些关键词一样,在处理三维信息时,也有自己的一套“价值判断”:
● 有的只关注和当前场景几何、视觉内容相邻的局部区域,大量重复观测的空间信息完全冗余;
● 有的会反复回看首帧内容,把它当作全局坐标的稳定参考基准;
● 还有的会长期锁定少数关键帧、相机相关token,这些内容就是维持长序列结构与时序一致性的“锚点”,除此之外的绝大多数历史信息,对后续推理几乎没有贡献。
这意味着,看似膨胀的“缓存”里,充满了大量重复、冗余的观测,只有一小部分信息才是真正被高频访问、持续发挥作用的“精华”。
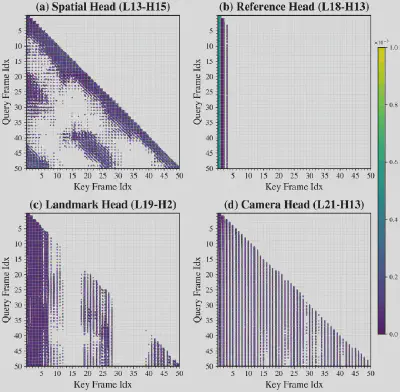
图5:Causal-VGGT的注意力模式,揭示了哪些历史信息才是真正的“关键少数”。
所以,问题不再是“如何让AI记住更多”,而是 “如何教AI学会‘挑着记’” 。
解法:给模型装上“智能记忆系统”,不丢关键信息,只清冗余
基于这个核心洞察,团队设计的STAC,从来都不是简单粗暴地“删缓存”,而是对历史信息做了一次彻底的“重组优化”——真正支撑推理的关键信息精准留存,重复冗余的空间信息高效压缩,核心靠三大模块实现:
1. 时序维度:打造永不丢失的“工作记忆”
在时间维度上,STAC会帮你留下三样东西:一个全局参考(首帧,就像家的坐标)、一段近期记忆(最近几帧,维持连续感)和几个 “锚点”(反复出现的关键地标)。这确保了时间线上的关键信息不丢失,类似于一个短时间的工作记忆。
2. 空间维度:构建全局统一的“长期地图”
对于那些离开“时间窗口”的旧记忆,STAC并不会扔掉,而是把它们重新整理、合并成一份更紧凑的空间记忆。相似的内容被压缩,差异大的内容则形成新的“地标”。原本线性膨胀的缓存,被改写成了更贴合场景几何结构的“长期地图”,可以被反复查阅。
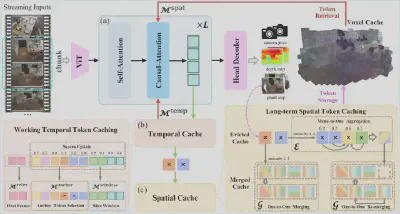
图6:STAC的工作流程:通过时空感知,将膨胀的缓存压缩为精炼的“工作记忆”和“空间地图”。
3. 执行优化:从“走一步算一步”到“小步快跑协同”
除了记忆系统的重构,STAC还对推理流程做了关键优化:它不再严格逐帧处理,而是把连续多帧打包成一个“块”联合优化。 这种基于块的多帧协同策略,在严格遵守流式推理约束的前提下,既让局部帧之间的信息交互更充分,进一步提升了时序一致性,还能大幅提升GPU的并行效率,让推理速度再上一个台阶。

结果:不只是省内存,而是改写了“膨胀定律”
在NRGBD和7-Scenes等公开数据集上,STAC交出了一份惊艳的答卷:
● 显存压缩:在STream3R模型上,总内存从19.75 GB骤降至2.20 GB,压缩了近10倍!
● 推理加速:速度从2.52 FPS飙升至10.53 FPS,提升了4倍!
● 质量不减:更惊人的是,在如此大幅度的压缩下,重建质量依然接近原始模型。
更重要的是,相比于简单粗暴的“滑动窗口”(只保留最近几帧),STAC在相同内存下,重建的场景结构更完整,细节一致性更好。这说明,它“忘掉”的,的确是冗余信息,而“记住”的,都是真正支撑几何一致性的精华。
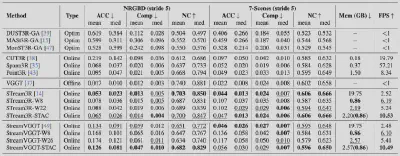
表1:STAC在显著降低内存、提升速度的同时,重建质量仍与原始模型高度接近。

图7:相比“一刀切”的滑动窗口(下),STAC(上)重建的场景更完整,细节更清晰。
总结与展望:迈向更聪明的“终身视觉系统”
STAC 的价值,从来都不止于 “给 KV Cache 做了一次压缩”。
它真正回答了一个更核心的命题:当视觉几何大模型从 “离线批量处理器”,转向 “7×24 小时持续运行的实时感知系统” 时,我们该如何管理它的历史记忆?
过往的流式模型,总在试图让模型 “记住一切”,最终被无限膨胀的内存拖垮;而 STAC 第一次让流式 3D 重建模型,学会了 “有选择地记忆”—— 记住真正关键的锚点,压缩重复冗余的信息,用更聪明的方式管理记忆,而非用更大的缓存硬扛。
这套时空感知的智能缓存思路,也为在线 SLAM、长视频时序理解、具身智能感知、实时多模态大模型等更多场景,提供了全新的技术启发:对于长期运行的智能系统来说,真正决定上限的,从来都不是更大的显存,而是更聪明的记忆方式。
论文发表
该工作已被计算机视觉顶级会议CVPR 2026录用。CVPR是计算机视觉与模式识别领域的顶级国际会议(CCF-A类),2026年录用率约为25.42%。
论文原文
论文标题:STAC: Plug-and-Play Spatio-Temporal Aware Cache Compression for Streaming3D Reconstruction
作者:王润泽,宋宇轩,蔡有城,刘利刚
单位:中国科学技术大学