GCL学术成果:CVPR 2026-ExpPortrait: 个性化表征与扩散模型相辅相成,重塑可控肖像动画新范式
近日,CVPR 2026接收成果出炉,来自中国科学技术大学数学科学学院GCL实验室的张举勇、郭玉东团队提出了ExpPortrait,聚焦“高表现力、高一致性、强可控”的人像视频生成任务,提出个性化头部表示与身份自适应表情迁移新框架,突破了传统2D关键点与低秩参数模型在身份保持和细粒度表情控制的瓶颈。如图1所示。该方法以更高保真度实现参考身份与驱动表情的精准融合,并在多项定量与定性实验中刷新表现,为可控数字人生成与高质量肖像动画带来全新方案。


图1:ExpPortrait结果展示
一、肖像视频生成困局:驱动信号的局限性
随着扩散模型的发展,肖像视频生成在过去几年基本遵循着相似的范式:从驱动视频中提取驱动信号输入扩散模型输出视频。这些驱动信号主要分为显式和隐式两类。
显式控制信号: 显式控制信号分为2D(如面部关键点)和3D(如SMPL-X、FlAME)两类,2D信号只能表现一定程度的眼睛、嘴巴的运动轨迹,不仅表现力较差,且在复杂头部运动下难以保持人物的3D一致性。与此同时,3D信号虽然能在一定程度上保持人物的3D一致,但其无法捕捉人物的高频细节,导致表情表现力与身份一致性。
隐式控制信号: 一些工作如Hunyuan Portrait,Live Portrait则试图通过从人物面部编码提取隐式运动特征进行驱动与生成,但隐式特征中存在着身份与表情的解耦不完全,往往面临严重的“身份泄漏”和“表情漂移”问题 。
为了突破现有控制方法的局限性,研究团队提出了ExpPortrait——一个基于个性化头部表示的肖像视频生成框架,使用一种精细化的3D驱动信号去引导扩散模型,生成高一致性、表现力、可控性的数字肖像生成。
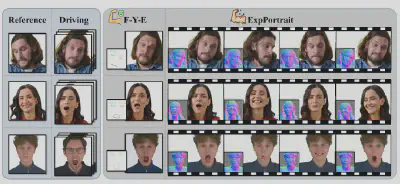
图2:ExpPortrait方法与现有显式控制方法的对比
二、个性化人头表示核心原理
3D参数化人头模型能够做到一定的3D一致性,但其表达能力有限,限制了视频生成的表现力,ExpPortrait希望在其一致性和解耦能力的基础上,进一步进行拓展,以SMPL-X网格为先验基础,在细分后,将身份与表情信息显式地解耦为两个互补偏移场:
● 静态全局偏移场:用于捕捉特定于该身份的高频几何细节(如嘴唇厚度、下颌线),在联合优化中每帧网格都共享。
● 动态逐帧偏移场:专门用于捕捉与特定表情相关的非线性皮肤形变(例如极其细微的肌肉拉扯和动态皱纹),在联合优化时每帧网格独立。
通过这两个偏移场,身份和表情在3D 几何层面实现了更进一步的解耦,且能够表现更为精细的人物身份信息与表情细节。
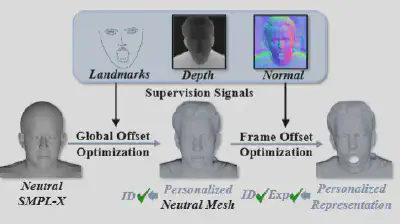
图2:个性化解耦人头表示
三、核心技术:面向高一致性与表现力的肖像生成框架
ExpPortrait希望借助精细化控制信号的表现力与扩散模型的泛化能力,同时攻克肖像生成领域的三大核心难题:
(1) 身份与表情的解耦
在联合优化两个偏移场时,对应表情偏移场的表情细节不应该出现在身份偏移场中。为此,研究团队引入了基于时空物理规律的解耦原则:通过对动态偏移场施加最小幅度惩罚,强制优化器将所有共享的静态几何特征解释为全局偏移,确保动态场只负责每帧动态表情偏移场的优化,实现了身份与表情的高度解耦。
(2) 身份自适应的表情迁移
跨身份驱动任务中,以往的方法最大的痛点是驱动后的表情与身份不兼容。例如,将一个老年人的表情迁移给一个儿童时,儿童的脸上不应该出现很多皱纹。为此,研究团队设计了身份自适应的表情迁移模块:利用轻量级的几何MLP,在驱动人物的表情编码条件下预测被驱动人物对应的动态偏移场,使迁移表情后的几何网格都能自然合理地贴合目标身份。
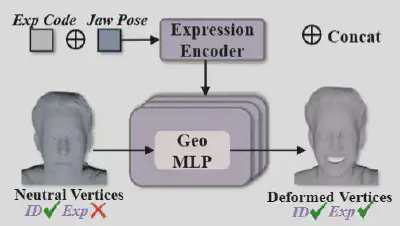
图3:表情迁移模块
(3) 条件视频扩散生成
构建了精细化3D人头表达后,团队使用基于DiT(Diffusion Transformer)架构的视频扩散模型Wan2.1作为生成骨干。将个性化表示渲染为法线贴图后,通过3D和2D卷积编码器提取时空与外观特征,作为高维条件注入DiT模块,实现最终的高表现力肖像生成。
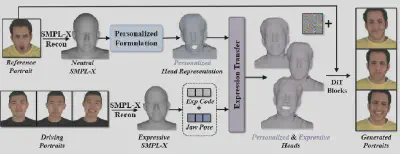
图4:ExpPortrait完整技术管线
四、实验结果
研究团队在VFHQ、CelebV-HQ和HDTF等共计约10小时的数据上进行了训练,并在RAVDESS和NeRSemble数据集上进行了验证。结果表明ExpPortrait在自驱动和跨身份驱动任务上超越了现有SOTA方法:
● 定量与定性领先: 在PSNR、SSIM以及反映身份保持的CSIM和运动准确度的AED/APD等核心指标上,ExpPortrait均显著优于LivePortrait、AniPortrait、Follow-Your-Emoji、Hunyuan Portrait以及 X-NeMo等主流基线。
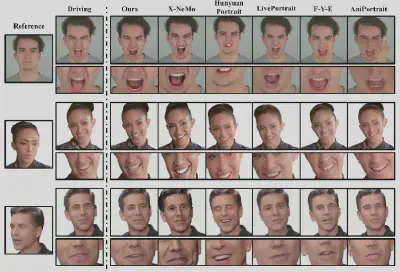
图5:自驱动定性实验结果

图6:交叉驱动定性实验结果
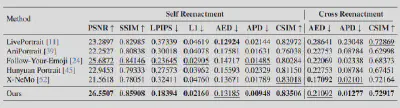
图7:定量实验结果
● 高保真的表情细节还原: 消融实验揭示了一个关键现象:仅仅使用基本的SMPL-X表示,生成的结果虽然能体现出大幅度的表情动作,但丢夫了很多表情细节信息。在引入个性化表示后,模型能够生成高保真且可控的肖像视频。
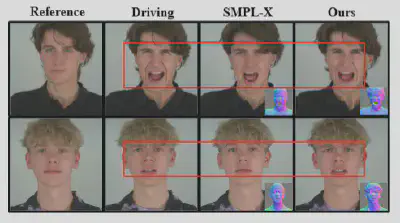
图8:个性化表达与SMPL-X生成效果对比
● 避免直接迁移的违和感: 消融实验也表明,直接把驱动人物的表情偏移量加在参考人物几何的身份网格上会导致表情细节的丢失或身份的不对应。而使用了自适应迁移模块可以先实现表情与身份的一致贴合,其生成的跨身份视频生动逼真,毫无违和感。

图9:表情迁移模块消融实验图
五、总结与展望
ExpPortrait引入了一种高保真度的个性化头部表示,该表示将特定于身份的静态几何形状与逐帧的表情细节解耦,并提出了一个表情迁移模块来实现表情的自然迁移,并结合DiT扩散模型来实现肖像视频生成。该框架能够在保持人物高一致性的前提下,实现高表现力与高可控性的肖像生成。
这种个性化表示作为一种解耦3D几何表示,能够自然地扩展到全身人体生成与驱动,也为其他下游任务(如语音驱动、高保真交互式虚拟化身应用)提供了实现基础。同时,将个性化人头表示和生成式模型结合,模型不仅能知道“这个人长什么样”,更能完美理解“这个人应该做出哪种程度的表情”,为数字人与虚拟内容创作迈向电影级可控表现力提供了一种全新的范式。
论文发表
该工作已被计算机视觉顶级会议CVPR 2026录用。CVPR是计算机视觉与模式识别领域的顶级国际会议(CCF-A类),2026年录用率约为25.42%。
论文原文
论文标题: ExpPortrait: Expressive Portrait Generation via Personalized Representation
作者: 王俊逸,郭玉东,郭勃阳,杨圣铭,张举勇
单位: 中国科学技术大学
项目主页:
https://ustc3dv.github.io/ExpPortrait/
相关工作
围绕高保真数字人的高效生成、编辑与驱动,张举勇、郭玉东课题组近年来开展了一系列系统性研究工作,累计约30篇论文发表于计算机视觉与计算机图形学领域顶刊顶会。与此工作紧密相关的部分论文如下:
- 可学习高斯嵌入引导的扩散肖像视频生成(SIGGRAPH Asia 2025). Constructing Diffusion Avatar with Learnable Embeddings. Xuan Gao, Jingtao Zhou, Dongyu Liu, Yuqi Zhou, Juyong Zhang.
- 统一多模态人像视频编辑(SIGGRAPH Asia 2024). Portrait Video Editing Empowered by Multimodal Generative Priors. Xuan Gao, Haiyao Xiao, Chenglai Zhong, Shimin Hu, Yudong Guo, Juyong Zhang.
- 基于NeRF的高效参数化人头模型(CVPR 2022). HeadNeRF: A Real-time NeRF-based Parametric Head Model. Yang Hong, Bo Peng, Haiyao Xiao, Ligang Liu, Juyong Zhang.
- 基于VAE的跨域表情迁移(TVCG 2022). Facial Expression Retargeting from Human to Avatar Made Easy. Juyong Zhang, Keyu Chen, Jianmin Zheng.
- 基于NeRF的音频驱动数字人像生成(ICCV 2021). AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis. Yudong Guo, Keyu Chen, Sen Liang, Yongjin Liu, Hujun Bao, Juyong Zhang.