GCL学术成果:CVPR 2026-告别模型加载卡顿与冗余:ProgressiveAvatars探索4D数字人渐进式流媒体新范式
近日,CVPR 2026接收成果出炉,来自中国科学技术大学数学科学学院GCL实验室的张举勇团队提出全新渐进式4D数字人表征ProgressiveAvatars。该工作为3DGS数字人资产引入了连续流媒体传输与渐进式渲染能力,有效缓解了传统方法在实时交互中面临的漫长加载等待问题。如图1所示,相较于依赖全量加载的GaussianAvatars,ProgressiveAvatars能够在受限网络下传输少量高斯即可实现初始响应,并随着数据流入实现画质的平滑提升。


图 1. 渐进式传输效果对比。
一、3D高斯数字人走向流媒体的困境
高保真、可实时渲染的3DGS技术,为沉浸式交互和三维数字人创建提供了良好的三维表达范式。然而,现有的3DGS数字人表达在实际的多用户社交VR或者沉浸式会议应用中,在网络带宽和计算资源波动时,还存在以下挑战:
1. 全量加载导致的启动延迟:主流方法将3DGS视为静态资产,需下载完整数据后方可渲染。在多用户场景下,这种模式极易引发带宽峰值与漫长的启动等待,破坏沉浸体验。
2. 离散LOD带来的切换卡顿与存储冗余:现有LOD方法多依赖离散范式,需存储同一资产的多个质量副本 。这不仅造成存储冗余与模型切换时的延迟,更无法实现细节的平滑增量累加与真正的渐进式渲染 。
3. 均匀扩展造成的资源分配不均: LoDAvatar和ArchitectHead等前期工作多采用均匀扩展策略(如均匀细分网格或增加UV分辨率)构建多层级结构 。这种缺乏针对性的方式易导致平滑区域过度细化、高频细节处却细分不足,未能实现计算与传输资源的最优配置 。
因此,探索一种既能保持动画驱动能力,又能随着数据流入平滑、高效地提升画质的流媒体表征方式,成为一个亟待解决的研究问题。
二、构建连续渐进式表征,实现平滑增量渲染

图 2. ProgressiveAvatars是一种渐进式表示方法,支持在带宽或算力受限的情况下自适应调整 3D 高斯数字人的渲染质量。
为了缓解上述流媒体场景下的困境,中科大张举勇团队提出了一种全新的渐进式三维数字人表征ProgressiveAvatars。ProgressiveAvatars采用统一的流式资产。其运行机制允许接收端在任意传输进度下,立即渲染当前已接收到的3D高斯数据子集。随着后续数据的不断流入,新到达的高斯点会自然地融合到现有画面中,而无需丢弃或替换之前的任何内容。这种持续累加细节的增量式渲染机制,使得数字人在获取少量数据时即可展现出基础的动画驱动形态,并在波动的网络与算力环境下,实现了从粗略到精细质量的平滑过渡。
三、技术解析:基于自适应隐式细分与重要性排序的渐进式架构
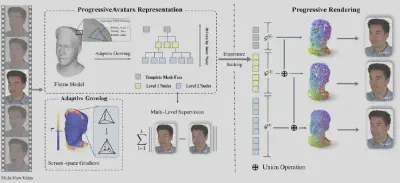
图 3. ProgressiveAvatars的整体框架概述。
ProgressiveAvatars能够兼顾响应速度与渲染质量。依托于架构设计,研究团队将整个管线解耦为以下三个核心模块:
1. 局部坐标绑定—维持多层级下的结构与动画一致性:为确保数字人在渐进式传输和细节叠加过程中始终保持可动画驱动,以FLAME头部模型作为基础拓扑结构。ProgressiveAvatars将3D高斯锚定在每个三角形面片的局部坐标系中。通过这种面片局部的参数化绑定,高斯点能够随着网格的形变而移动,从而在不同的表情和头部运动下,乃至跨越多个细节层级,均能保持结构和外观的一致性。
2. 多层级表征构建—自适应生长的隐式细分层次结构:为支持流媒体传输,ProgressiveAvatars依托隐式细分构建了锚定于网格的多层级表征。其基础层覆盖所有模板面片以保障初始渲染的完整性。随后,系统以屏幕空间梯度为引导,对高频区域进行自适应面片细分,向下扩展精细子层级。该树状结构不仅避免了均匀细分造成的算力浪费,更通过递归计算重心坐标的继承关系,将根节点的运动状态传递至任意子节点,确保了跨层级几何细节的动画稳定性。
3. 重要性排序—多层级三维结构的线性化数据流转化:为实现渐进式的流媒体传输,ProgressiveAvatars引入了重要性排序机制。系统结合高斯点的逐像素不透明度与累积透射率,计算每个面片及其绑定高斯点对渲染图像的贡献度得分。基于此得分,复杂的多层级三维资产被线性化为一维数据流。渲染阶段优先推送并激活高贡献度高斯点,确保早期渲染结果最大程度贴近完整模型,有效抑制了低权重内容提前加载所引发的颜色漂移与伪影。
四、结果展示:低带宽下的快速响应与渐进式高质量重建
为了验证该框架在实际流媒体场景中的表现,研究团队在NeRSemble数据集上进行了定性与定量实验。数据表明,ProgressiveAvatars在较低的数据预算下展现出了良好的渲染收益,并在保持了与现有先进方法相当的渲染水准:
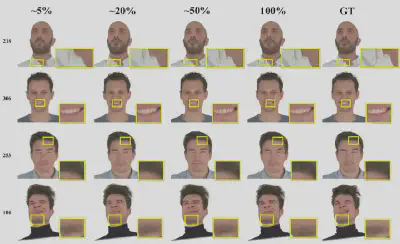
图 4. ProgressiveAvatars在NeRSemble数据集上不同传输百分比下的定性结果。
1. 低带宽下快速响应与增量渲染:仅需传输5%的基础数据(约2.60MB),ProgressiveAvatars即可渲染出结构完整且视觉可用的数字人,大幅缓解了受限带宽下的启动延迟。随着高层级数据持续流入,衬衫纽扣、牙齿和毛发等精细结构逐渐锐化,且在动态渲染中全程保持了高度的时间稳定性。
2. 超越均匀细分的资源效率: 相较于LoDAvatar中的均匀细分策略,自适应生长策略能够以更少的高斯点数量,实现更高的重建质量。 具体而言,ProgressiveAvatars 在五个层级下仅用120k个高斯点达到了28.29的PSNR,优于均匀细分三次(273k个高斯点,PSNR27.65)的表现。
3. 对标基线方法的重建效果与存储优势:100%传输完成时,该方法的渲染质量与目前先进的基线方法(如GaussianAvatars)处于同等水平。此外,相比于采用离散压缩管线(例如GaussianAvatars结合LightGaussian压缩需要227.2 MB来存储 10个层级),单一资产的ProgressiveAvatars降低了存储开销,仅需43.4 MB即可支持连续的任意速率渲染与平滑的质量细化。

图 5. 与现有先进方法的定性视觉对比。
五、总结与展望:拓展3D资产渐进式流媒体渲染的应用边界
ProgressiveAvatars提出了一种渐进式、可动画驱动的3D高斯数字人表征。该工作将传统依赖离散多副本的LOD切换范式,转化为单一、连续的流式资产。在实际应用中,该框架能够在不替换或删除已接收内容的前提下,实现从快速初始响应到高保真画质的平滑过渡。
这一特性的实现,对于在异构网络与不同设备终端之间高效传输3DGS内容具有重要的参考价值。更为重要的是,虽然本项研究主要聚焦于数字头部表征,但其提出的网格锚定的渐进式高斯层次结构本身具备良好的通用性。在未来的研究与工业落地中,该思路有望被拓展应用于通用3D资产乃至4D体积视频的渐进式流媒体传输与渲染中,为下一代XR 交互的资产分发管线提供坚实的技术支撑。
论文发表
该工作已被计算机视觉顶级会议 CVPR 2026 录用。CVPR 是计算机视觉与模式识别领域的顶级国际会议(CCF-A类),2026年录用率约为 25.42%。
论文原文
论文标题:ProgressiveAvatars: Progressive Animatable 3D Gaussian Avatars
作者:宋凯文,崔晋恺,张举勇
单位:中国科学技术大学 (University of Science and Technology of China)
项目主页:https://ustc3dv.github.io/ProgressiveAvatars/
相关工作
围绕高保真4D数字人的高效表征、重建与交互,张举勇课题组近年来开展了一系列系统性研究工作,累计约30篇论文发表于计算机视觉与计算机图形学领域顶刊顶会,与此工作紧密相关的部分论文如下:
- 基于单张图像的说话数字人建模(ICCV 2025)Expressive Talking Human from Single-Image with Imperfect Priors.Jun Xiang, Yudong Guo, Leipeng Hu, Boyang Guo, Yancheng Yuan, Juyong Zhang.
- 可物理仿真的穿衣三维数字人表征(TVCG 2025) PICA: Physics-Integrated Clothed Avatar. Bo Peng, Yunfan Tao, Haoyu Zhan, Yudong Guo, Juyong Zhang.
- 基于单目视频的穿衣数字人解耦重建(CVPR 2025) D3-Human: Dynamic Disentangled Digital Human from Monocular Video. Honghu Chen, Bo Peng, Yunnan Tao, Juyong Zhang.
- 面向超写实人头渲染的混合显式表征(CVPR 2025) HERA: Hybrid Explicit Representation for Ultra-Realistic Head Avatars.Hongrui Cai, Yuting Xiao, Xuan Wang, Jiafei Li, Yudong Guo, Yanbo Fan, Shenghua Gao, Juyong Zhang.
- 基于3DGS的高效可驱动三维数字人头表征(CVPR 2024) FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding.Jun Xiang, Xuan Gao, Yudong Guo, Juyong Zhang.
- 辐射场参数化人头表征(SIGGRAPH ASIA/ACM TOG 2022) Reconstructing Personalized Semantic Facial NeRF Models From Monocular.Video Xuan Gao, Chenglai Zhong, Jun Xiang, Yang Hong, Yudong Guo, Juyong Zhang.
- 基于单目视频的穿衣人体重建(CVPR 2022)SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video.Boyi Jiang, Yang Hong, Hujun Bao, Juyong Zhang.