GCL学术成果:CVPR 2026-解耦姿势×表情双控!DeX-Portrait 解锁高可控性的肖像动画
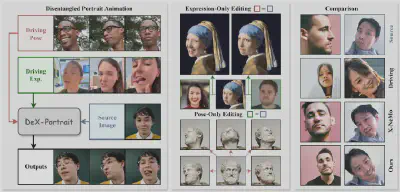
近日,CVPR 2026 论文录用结果正式公布,中国科学技术大学数学科学学院GCL实验室和华为、南京大学的研究团队提出全新肖像动画生成方法——DeX-Portrait,首次实现头部姿势、面部表情与身份特征的高保真解耦控制,为仅表情编辑、仅姿势编辑等肖像动画应用提供全新解决方案。


困局:从高保真到高可控的肖像驱动
想象一下,你手里有一张老照片。照片里的人看着你,但一切都静止了。
你多么希望,能让它重新动起来——转转头、眨眨眼、露出那个熟悉的笑容。
这,就是肖像动画的梦想。
扩散模型让肖像"活"了过来,却有一个致命缺陷:
头部姿势、面部表情、身份特征,三者像被绑在一起的绳子,牵一发而动全身。
想让照片中的人只改变表情、保持姿势不变?做不到。
想只调整头部角度、保留原有表情?还是做不到。
精细化创作场景,被挡在了技术的高墙之外。

破局:从"牵一发而动全身"到"解耦即自由"
我们的研究团队,问了一个简单却深刻的问题:
“为什么一定要绑在一起?"
DeX-Portrait 由此诞生。
他们像解毛线团一样,把运动信号一根一根拆开:
头部姿势 → 显式的RTS全局变换,独立控制;
面部表情 → 隐式潜码,精准捕捉;
身份特征 → 在生成中牢牢守住;
解耦,意味着自由。
现在,你可以让照片中的人只笑一笑,头不动;也可以让他只转转头,表情不变。
拆解难题:运动训练器的设计
团队面对的第一个问题是:如何让姿势和表情"分家”?
想象你在调一台老式收音机。频道和音量两个旋钮混在一起,想调音量,频道也跟着变——这就是当时肖像动画的困境。
研究团队决定,从头开始重建这套"控制系统"。
团队设计了一个基于GAN的运动训练器,它的工作方式像一位细心的"分拣员":
第一步,通过对3D潜特征的全局RTS变形,把头部姿势信息"刻"进去;
第二步,通过AdaIN方法,把表情向量"注"进去——嘴角上扬、眉毛微挑,精准捕捉;
第三步,搭配一系列图像增强策略,像给两个信号加上"隔离墙",强化它们的独立性。
最终输出的,是精准、完全解耦的姿势与表情驱动信号。
“就像把混在一起的红蓝两色墨水,重新分离成两瓶纯净的颜料。”
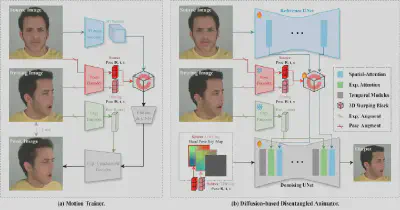
拆解难题:组合控制
信号有了,下一个难题是:如何把它们送进扩散模型,还不互相干扰?
这是之前没人解决的问题。表情向量注入时,总会"污染"姿势控制;姿势变换时,又容易"带走"表情信息。
团队首次提出了双分支姿势注入机制,像修了两条独立的高速公路,
第一分支:RTS→光线图→与噪声输入拼接,直接告诉模型"头往哪转";
第二分支:RTS→变形参考网络中间特征→与去噪网络特征拼接,从内部校准姿势生成。
双管齐下,精准控制。
更重要的是,表情向量从此不再产生干扰。它通过交叉注意力独立注入,走自己的通道。
最后的打磨:采样方式的重构
框架搭好了,生成效果还有最后一道关卡:身份一致性。
有时候,姿势和表情都对了,但生成的脸"不像同一个人"。这是扩散模型的老问题。
受FLOAT工作启发,团队在去噪阶段提出了渐进式CFG策略。
它的工作方式像一位耐心的画家:
“不是一笔涂完,而是一层一层上色。先确定姿势,再融入表情,每一步都让身份特征更稳固。”
通过分步融入姿势与表情条件,生成结果的身份一致性显著提升。

结语
团队在跨身份驱动与解耦驱动两大核心场景,与当前 SOTA 方法开展定量、定性对比实验。结果表明,DeX-Portrait 在真实场景中展现出最优的表现力与泛化能力,生成效果全面超越现有基线方法。


DeX-Portrait 突破了现有肖像动画生成的解耦控制瓶颈,为数字人创作、视频编辑、虚拟形象驱动等场景提供了高质量、高可控的技术方案,也为扩散模型在细粒度生成任务上的应用提供了新思路。
论文发表
该工作已被计算机视觉顶级会议CVPR 2026录用。CVPR是计算机视觉与模式识别领域的顶级国际会议(CCF-A类),2026年录用率约为25.42%。
论文原文
论文标题:DeX-Portrait: Disentangled and Expressive Portrait Animation via Explicit and Latent Motion Representations
作者:施羽翔¹,李哲²,王彦文³,朱昊³,曹汛³,刘利刚¹
单位:¹中国科学技术大学,²华为,³南京大学